
Door: Sophie Horsman, Marcio Fuckner en Pascal Wiggers (onderzoekers van de Hogeschool van Amsterdam)
In een sketch van de BBC Schotland zitten twee mannen vast in een lift, omdat de automatische spraakassistent van de lift hun Schotse accent niet verstaat. De mannen proberen de lift naar de elfde verdieping te krijgen, maar het systeem blijft vragen “Could you please repeat that?” en de lift komt niet in beweging.
Deze parodie laat zien dat nieuwe technologieën die gebruikmaken van spraakherkenning niet voor iedereen werken, soms tot frustratie aan toe. Ondanks dat de technologie de afgelopen jaren enorm is verbeterd, is het welbekend dat automatische spraakherkenning (automatic speech recognition: ASR) niet voor iedereen even goed werkt. De spraak van jonge kinderen en ouderen, maar ook die van mensen met een (sterk) accent wordt door een ASR-systeem vaak niet goed herkend.
Onderzoeksproject: Inclusieve spraakherkenning
Deze bias – het slechter presteren van een spraakherkenningsmodel voor bepaalde sprekersgroepen – is het onderwerp van een onderzoeksproject binnen DRAMA (Designing Responsible AI Media Applications). Samen met RTL hebben wij gekeken naar de potentiële bias in twee recente en veelgebruikte spraakherkenningssystemen. RTL gebruikt automatische spraakherkenning voornamelijk voor het automatisch ondertitelen van hun televisieprogramma’s, zodat ook slechthorenden en doven deze programma’s kunnen volgen. De onderzochte spraakherkenners zijn Wav2vec2 (ontwikkeld door Meta AI) en Whisper (ontwikkeld door OpenAI). Onze methodologie is geïnspireerd op eerder onderzoek van de TU Delft die bias onderzocht in het Kaldi spraakherkenningssysteem (Feng et al., 2023). In de afbeelding hierboven is onze onderzoeksopzet schematisch weergegeven.
We gebruikten het JASMIN-corpus als test dataset. Dit is een spraakcorpus dat een grotere collectie van spraakfragmenten heeft verzameld van sprekers die onvoldoende zijn gerepresenteerd in CGN, het grootste Nederlandse gesproken spraakcorpus. De JASMIN-dataset bevat spraakfragmenten van zowel voorgelezen teksten als dialogen tussen mensen en computers. Het bevat zowel Nederlandstalige als Vlaamse spraak en bevat spraak van kinderen (tussen de 6 en 18 jaar), senioren (65+’ers) en anderstaligen (met een niet Nederlandstalige afkomst). JASMIN heeft een representatieve verdeling tussen mannelijke en vrouwelijke sprekers.
We hebben een pipeline gemaakt waarin audiofragmenten uit de JASMIN-corpus door het ASR-systeem zijn getranscribeerd. Deze output is vervolgens vergeleken met de door mensen geannoteerde transcriptie. Om te evalueren hoe goed de automatische transcripties zijn, worden gangbare metrics gebruikt, zoals WER (Word Error Rate: het percentage fout voorspelde woorden) en CER (Character Error Rate: het percentage fout voorspelde karakters). De afbeelding bovenaan dit artikel toont de evaluatie pipeline.
Nog steeds aanzienlijke bias
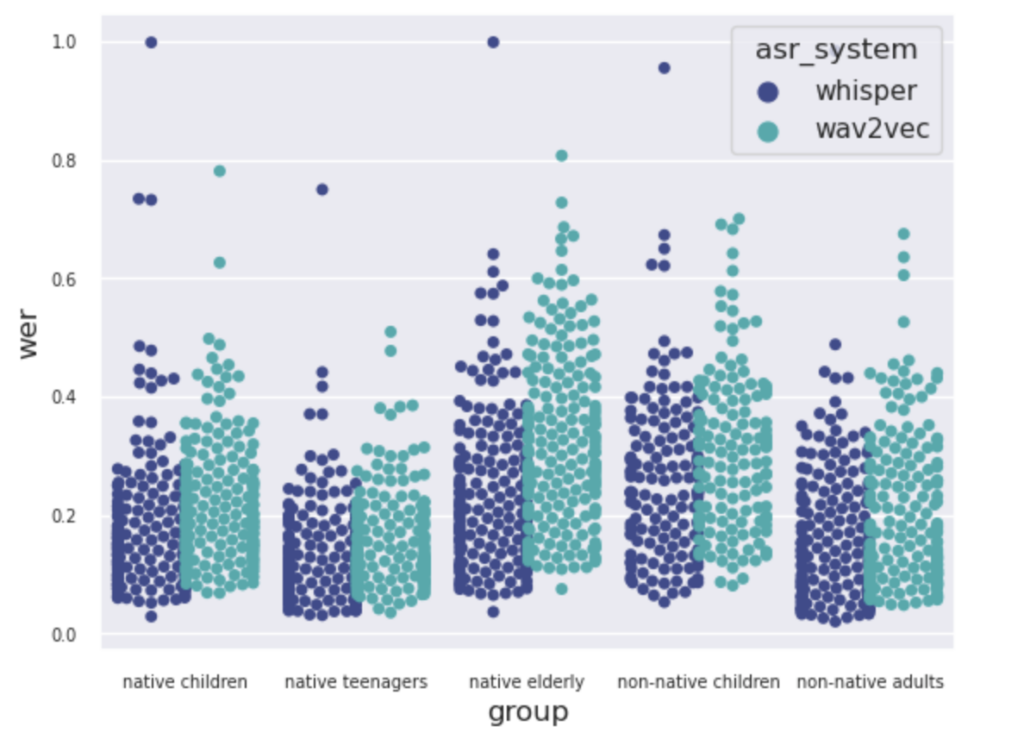
Alhoewel moderne spraakherkenners een stuk beter presteren in vergelijking met eerdere spraakherkenners, zien we dezelfde trends (zoals in de literatuur beschreven) wat betreft verschillen tussen sprekersgroepen. Over het algemeen zien we dat de spraak van anderstaligen significant slechter wordt herkend. Daarnaast wordt de spraak van jonge kinderen (7-12 jaar) en ouderen (65+) slechter herkend dan dat van tieners – waarvan de spraak waarschijnlijk het dichtst bij die van volwassenen ligt. De spraak van vrouwen wordt over het algemeen net wat beter herkend dan de spraak van mannen.
Als we de twee spraakherkenners met elkaar vergelijken, zien we dat Whisper voor elke sprekersgroep betere prestaties levert dan Wav2vec2. Daarnaast zien we dat de verschillen tussen sprekersgroepen wat kleiner zijn geworden, maar nog steeds aanwezig zijn. Het nadeel van een model als Whisper is dat in een klein aantal gevallen er totale onzin wordt getranscribeerd (met een WER van bijna 1.0). Dit staat bekend als ‘hallucinatie’ en hierover wordt in de spraakherkenningsgemeenschap veel gediscussieerd waarom dit gebeurt en hoe dit uit het model moet worden gehaald. Het probleem met hallucinatie is dat – ook al gebeurt het in enkele gevallen – je zo’n systeem altijd extra zal moeten controleren voordat het in een automatische pipeline kan worden opgenomen. In de afbeelding hieronder zijn de onderzoeksresultaten weergegeven.
Vervolgstappen
We weten nu dat moderne spraakherkenners nog steeds aanzienlijke bias bevatten. Het is onwaarschijnlijk dat deze bias er ooit helemaal uitgaat, omdat dit een inherent onderdeel lijkt te zijn van spraaktechnologie. Nota bene: ook mensen verstaan bepaalde groepen mensen beter dan anderen. Hoe geven we mediaorganisaties desondanks tools in handen om de komende jaren te blijven werken aan meer inclusieve spraakherkenning? Daar hebben we het volgende op bedacht:
Model cards
Allereerst stellen we voor om met (interactieve) model cards te gaan werken. Ontwikkelaars van spraakherkenningssystemen kunnen deze gebruiken om zelf de bias in ASR-systemen te analyseren. We hebben dit samen met studenten van de minor Applied AI (HvA) verkend (Sept ‘22-Jan ‘23). Zij hebben voor RTL een interactieve model card gemaakt voor het model Wav2vec2, zie de afbeelding hieronder. Met deze interactieve model card krijgen ontwikkelaars inzicht in de prestaties van het model, waarbij de verschillen tussen sprekersgroepen inzichtelijk gemaakt worden. Daarnaast kunnen zij – met behulp van de model card – specifieke transcripties bestuderen om inzicht te krijgen in de beperkingen van het model, zodat zij na kunnen gaan bij welke spreker of bij welke input het model moeite krijgt, en wat voor type fouten er optreden.
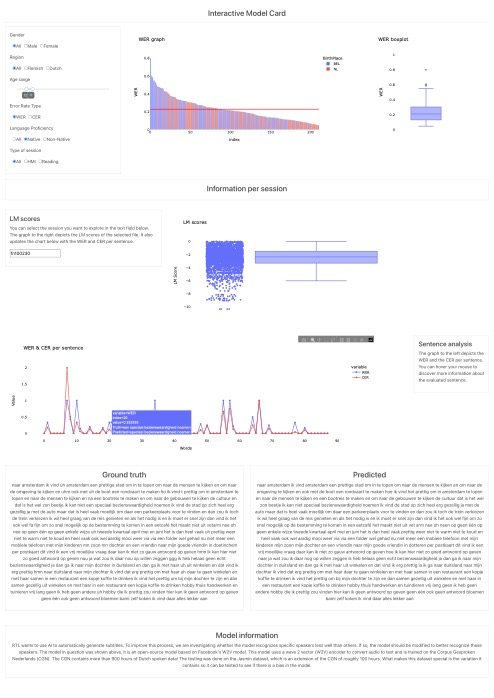
Om de potentie van model cards verder te onderzoeken, hebben wij enkele keren een workshop gegeven (waaronder op de Dutch Media Week). Een bredere doelgroep kan daardoor meedenken hoe zo’n interactieve model card er idealiter uit komt te zien, zodat het voor verschillende doelgroepen duidelijk wordt wat het model wel en niet kan.
Spraakherkenners finetunen
Een tweede interessante verkenning is om te kijken of we bestaande spraakherkenners kunnen finetunen met meer diverse Nederlandstalige spraakdata, of synthetische data (kunstmatig gecreëerde spraakdata). Om er uiteindelijk voor te zorgen dat de verschillen in prestatie tussen sprekersgroepen zo minimaal mogelijk worden. We hebben dit het afgelopen semester (Jan ‘23-Juni ‘23) in verschillende studentenprojecten onderzocht. Een van de masterstudenten Applied AI (Lisanne Henzen) gaat binnenkort haar afstudeerproject over het finetunen van Whisper met behulp van synthetische data op BNAIC presenteren. De lessen die we uit deze projecten hebben geleerd zullen we binnenkort in een technische blog uitgebreider beschrijven. Stay tuned!
Referenties:
Feng, S., Halpern, B. M., Kudina, O., & Scharenborg, O. (2023). Towards inclusive automatic speech recognition. Computer Speech & Language, 101567, Chicago.
M. Fuckner, S. Horsman, P. Wiggers and I. Janssen, “Uncovering Bias in ASR Systems: Evaluating Wav2vec2 and Whisper for Dutch speakers,” 2023 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Bucharest, Romania, 2023, pp. 146-151, doi: 10.1109/SpeD59241.2023.10314895.